Location, e.g., Countries, states, cities, and point-of-interests, are central to news, emergency events, and people’s daily lives. Automatic identification of locations associated with or mentioned in documents has been explored for decades. As one of the most popular online social network platforms, Twitter has attracted a large number of users who send millions of tweets on daily basis. Due to the world-wide coverage of its users and real-time freshness of tweets, location prediction on Twitter has gained significant attention in recent years. Research efforts are spent on dealing with new challenges and opportunities brought by the noisy, short, and context-rich nature of tweets. In proposed system, an overall picture of location prediction on Twitter is offered. Specifically, the prediction of user home locations, tweet locations, and mentioned locations is considered. By summarizing Twitter network, tweet content, and tweet context as potential inputs, it is structurally highlighted how the problems depend on these inputs
Location Prediction in Twitter using Machine learning Techniques
—————————————————————————
Implementation Details:
——————————————–
1. Data Collection:
——————————–
1. Collect Live tweet based on location (we used three locations such as Chennai, Mumbai, Kerala)
2. Live tweets are collected as json file
2. Data Pre-processing:
—————————————
Tweet text is pre-processed with following steps
1. Remove extra characters and special characters
2. Convert all words to Capitalize first letter (needed to apply geography package)
3. If tweet location & user location is null, then remove the tweet
4. If tweet location is null, then apply home location as tweet location
5. If no location is mentioned in tweet then remove the tweet
6. Apply Geodata on tweet_text to identify location
7. Apply Lableencoder to convert text (location from tweet_text) to integer value”Lvalue” (e.g Chennai=1, Mumbai=2, Kerala=3)
6. Write the pre-processed dataset as csv file with following features
a. Tweet ID
b. Name
c. Screen name
d. Tweet Text
e. Home location
f. Tweet location
g. Mentioned location
h. Lvalue (location value)
3. Split Training Set & test Set
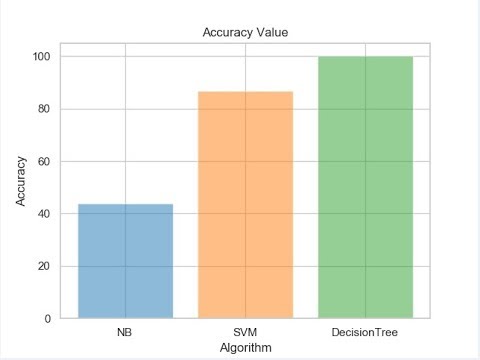
4. Apply Naive Bayes, SVM and Decision Tree algorithm
5. Calculate and compare accuracy and error values for all above algorithm